Kick Off, Improve, Win
Become the #1 Player, No Excuses, Just Results
Let’s aim higher! Unlock our backlink power for better rankings, more visitors, and a stronger online presence.




Our Specialized Services
Press Release
Boost visibility with strategic press releases 90+ DA Links.
Guest Posts
Elevate rankings and authority with our curated service.
Local SEO
Boost your local search impact with tailored strategies.
Customized Links
Tailor-made solutions that fit your budget and needs.
Welcome to Dot Mirror, where your SEO and link-building aspirations transform into tangible successes.
Our crown jewel, the Mega Rank Booster package, is specifically designed for online business owners like you, aiming to not just compete but dominate the digital landscape.
Join over 5,000 businesses that have already elevated their online presence with our unparalleled SEO and link-building services.
Mega Rank Booster: The Ultimate SEO Pack
// The Mega Rank Booster (MRB) package offers a monthly service focused on boosting your website to the top of Google’s rankings with quality link building and content marketing strategies. //
MRB: X3 Formula
MRB: Features
MRB: Quality
MRB: Outcome
MRB: X3 Formula
Discover our formula: Here’s how we’ll propel your business to new heights.
- X1: Premium Press Release Links
- X2: Niche-Relevant Guest Posts
- X3: Authority Focused Guest Posts
We’ll secure content backlinks from thousands of premier sites, including
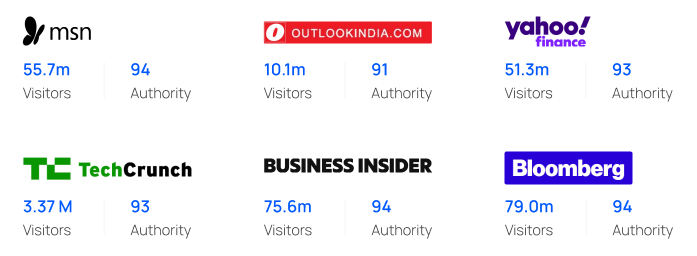
90+
Backlinks from sites with a DA of 50 to 90+ are ideal for boosting site ranking and content visibility.
MRB: Features
✔️ Contextual, Controlled, Quality-Driven Backlink Strategy
- Quality: Genuine sites, vetted for real engagement.
- Contextual Backlinks: Every backlink is relevant and impactful.
- Natural Links: Links placed for a natural profile and extra value.
- Control: Approve all domains before we initiate link placement.
- White Hat Links: Secure future-proof links for ranking longevity.
- Content: Crafted by native English writers for seamless integration.
- High Domain Authority: Only sites with strong SEO metrics are used.
❌ We avoid link sellers, poor content, high spam scores, non-English or slow sites, PBNs, and those missing essential features or exhibiting poor visitor trends and design.
MRB: Quality
Our Commitment to Quality: ❌ What We Avoid
In upholding high SEO quality and integrity, we strictly avoid:
- Content: Thin, poorly written, or non-original content.
- Integrity: Link sellers, spammy bios, PBNs, sites with spam history.
- Technical: Sites with slow load, high spam scores, no SSL, or poor optimization.
- Usability: Poorly designed, disorganized, lacking key pages (about, contact).
- Authority: Non-English, irrelevant directories, bad names, guest-post dominated.
- Legality: Sites with objectionable content or missing copyright.
- Performance: Sites with declining visitors or erratic traffic.
- Strategy: Irrelevant content categories, irregular publishing.
MRB: Outcome
Level Up Your Digital Game: Experience Visible Results!
Maximize your online visibility and impact with strategic SEO enhancements:
- Increased Visibility: More site visitors.
- Enhanced Link Juice: Greater link value.
- Improved SEO: Better optimization scores.
- Climbing Ranks: Peak search result positions.
- Boosted Authority: Higher domain credibility.
- More: Strengthen Your Web Presence Further.
110%
MRB: Our premier services guarantee a 110% success rate.

Unlock your competitive edge with our Mega Rank Booster strategy, designed to outshine your competitors. Discover how our tailored packages can elevate your rankings and showcase the impressive results of our services.

Popular Strategy
about Dot Mirror
We Combine Smart SEO with Custom Strategies
Dot Mirror specializes in improving your website’s rank and visibility using smart, personalized SEO tactics. We analyze and craft unique strategies to get your site noticed more online, leading to better results. Our work has also helped clients earn over $750,00 in sales and attracted over 20K leads, showing how well our methods work.
Impressive Growth: Our SEO boosts client revenue and visibility.
Client Retention: 100% retention for over three years proves our strategy works.
Partnership with Leaders: Leading startups choose us for growth.
Global Expertise: Over 20 top SEO and digital experts deliver unmatched service.
Driving digital revenue for our 3000+ satisfied customers
88%
Average Traffic Increase for Clients
“I've had the pleasure of collaborating with the dotMirror team for my website. Their SEO service has proven to be the best decision I've made for my business to date. I already saw some great improvements. What I appreciate the most are their quick responses to my question. Keep rocking!!”
AI Desk by Collov AIJamie L
“Special thanks to dotMirror digital marketing for doing a great job on placement for our recent links order. They were timely and now it's been awhile, links are still working.
Definitely appreciate the professional service received, links are not always equal and we liked that the links were placed for best results..”
Inner Vision ProCatalin Zorzini
Previous
Next






Get your free link-building audit
- 30-min strategy call
- In- depth audit
- Custom Growth Roadmap
Why dot mirror
How we drive revenue
BUILD AUTHORITY WITH QUALITY LINKS
Ready to boost your site's authority? Partner with us for proven link-building strategies that elevate your position in search results.
CRAFT & EXECUTE LINK-BUILDING CAMPAIGNS
Harness the power of strategic link acquisition to drive meaningful traffic and strengthen your online credibility.
ANALYZE & OPTIMIZE YOUR LINK PROFILE
Leverage our expertise to analyze your current link profile, identifying opportunities for growth and eliminating weaknesses.
ENHANCE YOUR BRAND'S ONLINE INFLUENCE
With consistent and targeted link-building efforts, solidify your brand's presence online, creating lasting impressions that convert visitors into loyal customers.
